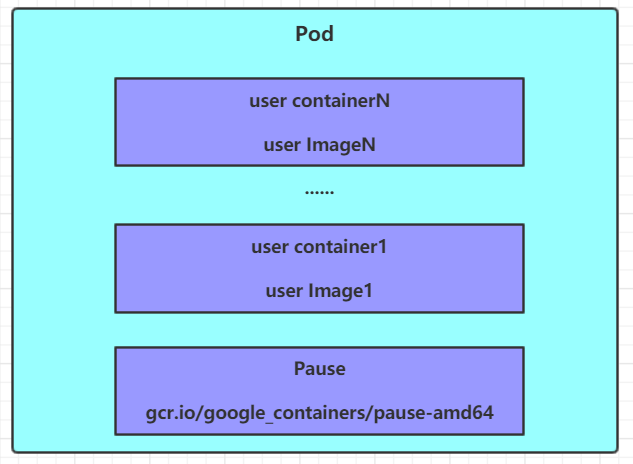
# 创建Pod [root@masterpod]# kubectl apply -f pod-base.yaml pod/pod-base created
# 查看Pod状况 # READY 1/2 : 表示当前Pod中有2个容器,其中1个准备就绪,1个未就绪 # RESTARTS : 重启次数,因为有1个容器故障了,Pod一直在重启试图恢复它 [root@masterpod]# kubectl get pod -n dev NAME READY STATUS RESTARTS AGE pod-base1/2 Running 495s
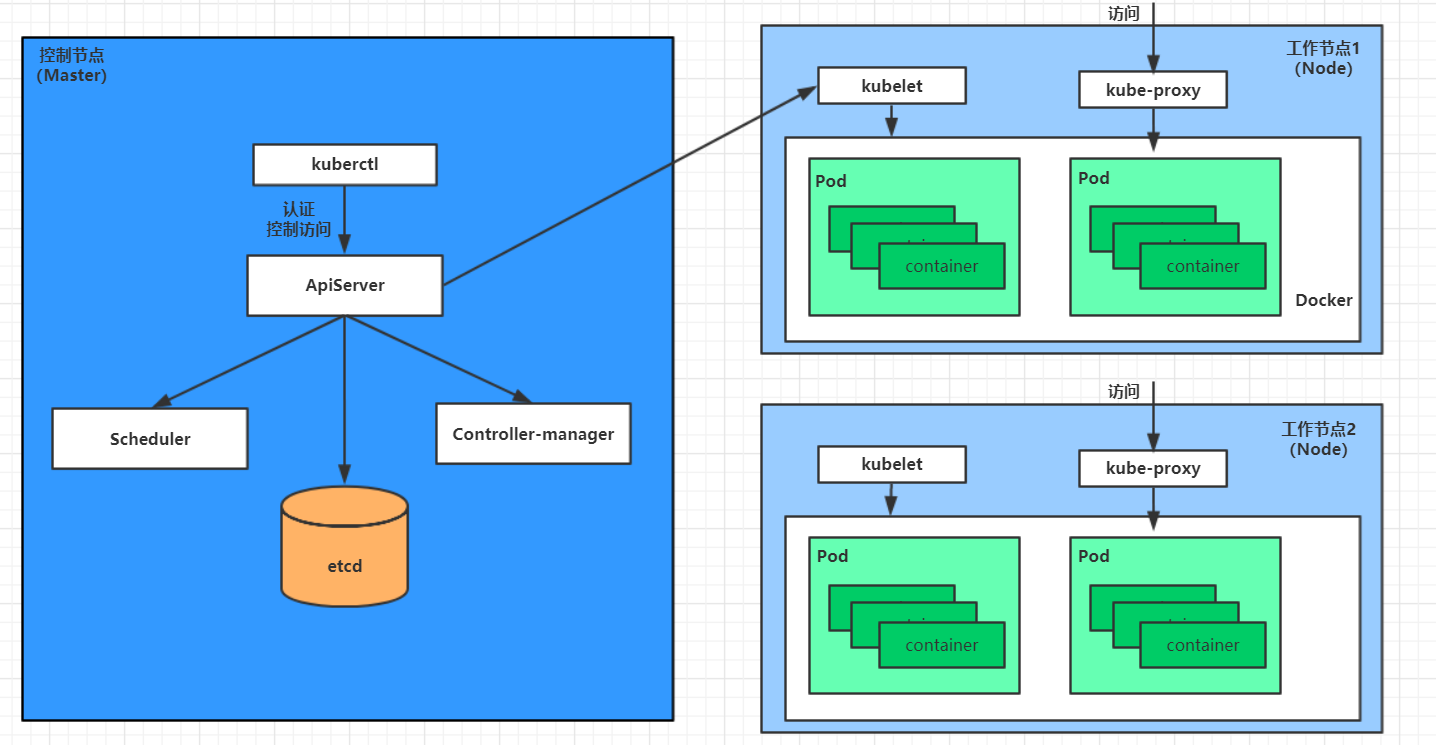
# 可以通过describe查看内部的详情 # 此时已经运行起来了一个基本的Pod,虽然它暂时有问题 [root@masterpod]# kubectl describe pod pod-base -n dev
# 创建Pod [root@masterpod]# kubectl create -f pod-imagepullpolicy.yaml pod/pod-imagepullpolicy created
# 查看Pod详情 # 此时明显可以看到nginx镜像有一步Pulling image "nginx:1.17.1"的过程 [root@masterpod]# kubectl describe pod pod-imagepullpolicy -n dev ...... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled <unknown> default-scheduler Successfully assigned dev/pod-imagePullPolicy to node1 Normal Pulling 32s kubelet, node1 Pulling image "nginx:1.17.1" Normal Pulled 26s kubelet, node1 Successfully pulled image "nginx:1.17.1" Normal Created 26s kubelet, node1 Created container nginx Normal Started 25s kubelet, node1 Started container nginx Normal Pulled 7s (x3 over 25s) kubelet, node1 Container image "busybox:1.30" already present on machine Normal Created 7s (x3 over 25s) kubelet, node1 Created container busybox Normal Started 7s (x3 over 25s) kubelet, node1 Started container busybox
# 创建pod [root@master ~]# kubectl create -f pod-initcontainer.yaml pod/pod-initcontainer created
# 查看pod状态 # 发现pod卡在启动第一个初始化容器过程中,后面的容器不会运行 root@master ~]# kubectl describe pod pod-initcontainer -n dev ........ Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 49s default-scheduler Successfully assigned dev/pod-initcontainer to node1 Normal Pulled 48s kubelet, node1 Container image "busybox:1.30" already present on machine Normal Created 48s kubelet, node1 Created container test-mysql Normal Started 48s kubelet, node1 Started container test-mysql
# 动态查看pod [root@master ~]# kubectl get pods pod-initcontainer -n dev -w NAME READY STATUS RESTARTS AGE pod-initcontainer0/1 Init:0/2015s pod-initcontainer0/1 Init:1/2052s pod-initcontainer0/1 Init:1/2053s pod-initcontainer0/1 PodInitializing 089s pod-initcontainer1/1 Running 090s
# 接下来新开一个shell,为当前服务器新增两个ip,观察pod的变化 [root@master ~]# ifconfig ens33:1 192.168.109.201 netmask 255.255.255.0 up [root@master ~]# ifconfig ens33:2 192.168.109.202 netmask 255.255.255.0 up
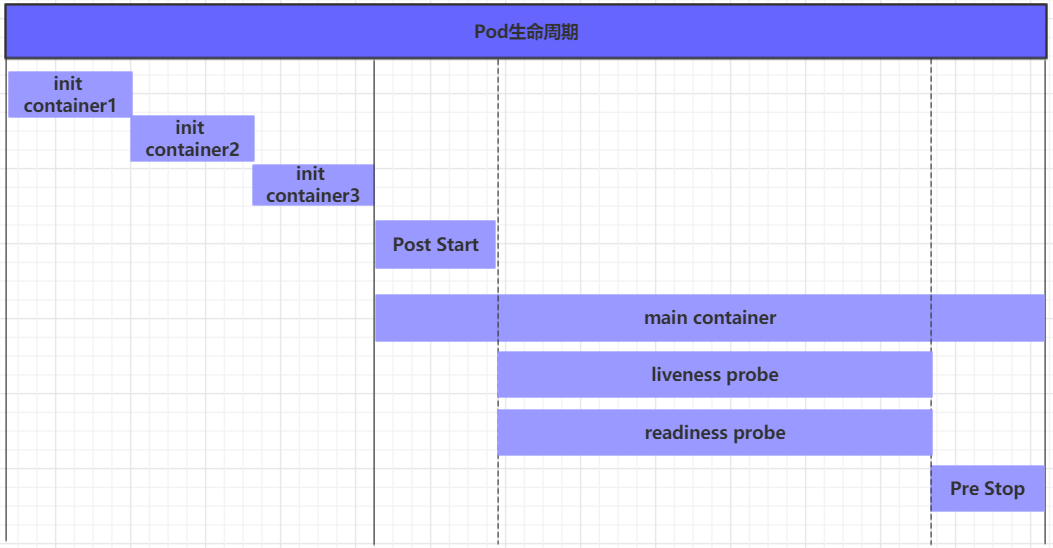
# 创建pod [root@master ~]# kubectl create -f pod-hook-exec.yaml pod/pod-hook-exec created
# 查看pod [root@master ~]# kubectl get pods pod-hook-exec -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE pod-hook-exec1/1 Running 029s 10.244.2.48 node2
# 创建Pod [root@master ~]# kubectl create -f pod-liveness-exec.yaml pod/pod-liveness-exec created
# 查看Pod详情 [root@master ~]# kubectl describe pods pod-liveness-exec -n dev ...... Normal Created 20s (x2 over 50s) kubelet, node1 Created container nginx Normal Started 20s (x2 over 50s) kubelet, node1 Started container nginx Normal Killing 20s kubelet, node1 Container nginx failed liveness probe, will be restarted Warning Unhealthy 0s (x5 over 40s) kubelet, node1 Liveness probe failed: cat: can't open '/tmp/hello11.txt': No such file or directory # 观察上面的信息就会发现nginx容器启动之后就进行了健康检查 # 检查失败之后,容器被kill掉,然后尝试进行重启(这是重启策略的作用,后面讲解) # 稍等一会之后,再观察pod信息,就可以看到RESTARTS不再是0,而是一直增长 [root@master ~]# kubectl get pods pod-liveness-exec -n dev NAME READY STATUS RESTARTS AGE pod-liveness-exec 0/1 CrashLoopBackOff 2 3m19s # 当然接下来,可以修改成一个存在的文件,比如/tmp/hello.txt,再试,结果就正常了......
# 创建Pod [root@master ~]# kubectl create -f pod-liveness-tcpsocket.yaml pod/pod-liveness-tcpsocket created
# 查看Pod详情 [root@master ~]# kubectl describe pods pod-liveness-tcpsocket -n dev ...... Normal Scheduled 31s default-scheduler Successfully assigned dev/pod-liveness-tcpsocket to node2 Normal Pulled <invalid> kubelet, node2 Container image "nginx:1.17.1" already present on machine Normal Created <invalid> kubelet, node2 Created container nginx Normal Started <invalid> kubelet, node2 Started container nginx Warning Unhealthy <invalid> (x2 over <invalid>) kubelet, node2 Liveness probe failed: dial tcp 10.244.2.44:8080: connect: connection refused # 观察上面的信息,发现尝试访问8080端口,但是失败了 # 稍等一会之后,再观察pod信息,就可以看到RESTARTS不再是0,而是一直增长 [root@master ~]# kubectl get pods pod-liveness-tcpsocket -n dev NAME READY STATUS RESTARTS AGE pod-liveness-tcpsocket0/1 CrashLoopBackOff 23m19s
# 创建Pod [root@master ~]# kubectl create -f pod-liveness-httpget.yaml pod/pod-liveness-httpget created
# 查看Pod详情 [root@master ~]# kubectl describe pod pod-liveness-httpget -n dev ....... Normal Pulled 6s (x3 over 64s) kubelet, node1 Container image "nginx:1.17.1" already present on machine Normal Created 6s (x3 over 64s) kubelet, node1 Created container nginx Normal Started 6s (x3 over 63s) kubelet, node1 Started container nginx Warning Unhealthy 6s (x6 over 56s) kubelet, node1 Liveness probe failed: HTTP probe failed with statuscode: 404 Normal Killing 6s (x2 over 36s) kubelet, node1 Container nginx failed liveness probe, will be restarted # 观察上面信息,尝试访问路径,但是未找到,出现404错误 # 稍等一会之后,再观察pod信息,就可以看到RESTARTS不再是0,而是一直增长 [root@master ~]# kubectl get pod pod-liveness-httpget -n dev NAME READY STATUS RESTARTS AGE pod-liveness-httpget1/1 Running 53m17s
#创建Pod [root@master ~]# kubectl create -f pod-nodename.yaml pod/pod-nodename created
#查看Pod调度到NODE属性,确实是调度到了node1节点上 [root@master ~]# kubectl get pods pod-nodename -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE ...... pod-nodename1/1 Running 056s 10.244.1.87 node1 ......
# 接下来,删除pod,修改nodeName的值为node3(并没有node3节点) [root@master ~]# kubectl delete -f pod-nodename.yaml pod "pod-nodename" deleted [root@master ~]# vim pod-nodename.yaml [root@master ~]# kubectl create -f pod-nodename.yaml pod/pod-nodename created
#再次查看,发现已经向Node3节点调度,但是由于不存在node3节点,所以pod无法正常运行 [root@master ~]# kubectl get pods pod-nodename -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE ...... pod-nodename0/1 Pending 06s <none> node3 ......
#创建Pod [root@master ~]# kubectl create -f pod-nodeselector.yaml pod/pod-nodeselector created
#查看Pod调度到NODE属性,确实是调度到了node1节点上 [root@master ~]# kubectl get pods pod-nodeselector -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE ...... pod-nodeselector1/1 Running 047s 10.244.1.87 node1 ......
# 接下来,删除pod,修改nodeSelector的值为nodeenv: xxxx(不存在打有此标签的节点) [root@master ~]# kubectl delete -f pod-nodeselector.yaml pod "pod-nodeselector" deleted [root@master ~]# vim pod-nodeselector.yaml [root@master ~]# kubectl create -f pod-nodeselector.yaml pod/pod-nodeselector created
#再次查看,发现pod无法正常运行,Node的值为none [root@master ~]# kubectl get pods -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE pod-nodeselector0/1 Pending 02m20s <none> <none>
# 查看详情,发现node selector匹配失败的提示 [root@master ~]# kubectl describe pods pod-nodeselector -n dev ....... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling <unknown> default-scheduler0/3 nodes are available: 3 node(s) didn't match node selector. Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
# 创建pod [root@master ~]# kubectl create -f pod-nodeaffinity-required.yaml pod/pod-nodeaffinity-required created
# 查看pod状态 (运行失败) [root@master ~]# kubectl get pods pod-nodeaffinity-required -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE ...... pod-nodeaffinity-required0/1 Pending 016s <none> <none> ......
# 查看Pod的详情 # 发现调度失败,提示node选择失败 [root@master ~]# kubectl describe pod pod-nodeaffinity-required -n dev ...... Warning FailedScheduling <unknown> default-scheduler0/3 nodes are available: 3 node(s) didn't match node selector. Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
#接下来,停止pod [root@master ~]# kubectl delete -f pod-nodeaffinity-required.yaml pod "pod-nodeaffinity-required" deleted
# 修改文件,将values: ["xxx","yyy"]------> ["pro","yyy"] [root@master ~]# vim pod-nodeaffinity-required.yaml
# 再次启动 [root@master ~]# kubectl create -f pod-nodeaffinity-required.yaml pod/pod-nodeaffinity-required created
# 此时查看,发现调度成功,已经将pod调度到了node1上 [root@master ~]# kubectl get pods pod-nodeaffinity-required -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE ...... pod-nodeaffinity-required1/1 Running 011s 10.244.1.89 node1 ......
# 创建pod [root@master ~]# kubectl create -f pod-nodeaffinity-preferred.yaml pod/pod-nodeaffinity-preferred created
# 查看pod状态 (运行成功) [root@master ~]# kubectl get pod pod-nodeaffinity-preferred -n dev NAME READY STATUS RESTARTS AGE pod-nodeaffinity-preferred1/1 Running 040s
# 启动pod [root@master ~]# kubectl create -f pod-podaffinity-required.yaml pod/pod-podaffinity-required created
# 查看pod状态,发现未运行 [root@master ~]# kubectl get pods pod-podaffinity-required -n dev NAME READY STATUS RESTARTS AGE pod-podaffinity-required0/1 Pending 09s
# 查看详细信息 [root@master ~]# kubectl describe pods pod-podaffinity-required -n dev ...... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling <unknown> default-scheduler0/3 nodes are available: 2 node(s) didn't match pod affinity rules, 1 node(s) had taints that the pod didn't tolerate.
# 接下来修改 values: ["xxx","yyy"]----->values:["pro","yyy"] # 意思是:新Pod必须要与拥有标签podenv=xxx或者podenv=yyy的pod在同一Node上 [root@master ~]# vim pod-podaffinity-required.yaml
# 然后重新创建pod,查看效果 [root@master ~]# kubectl delete -f pod-podaffinity-required.yaml pod "pod-podaffinity-required" deleted [root@master ~]# kubectl create -f pod-podaffinity-required.yaml pod/pod-podaffinity-required created
# 发现此时Pod运行正常 [root@master ~]# kubectl get pods pod-podaffinity-required -n dev NAME READY STATUS RESTARTS AGE LABELS pod-podaffinity-required1/1 Running 06s <none>
[root@master ~]# kubectl get pods -n dev -o wide --show-labels NAME READY STATUS RESTARTS AGE IP NODE LABELS pod-podaffinity-required1/1 Running 03m29s 10.244.1.38 node1 <none> pod-podaffinity-target1/1 Running 09m25s 10.244.1.37 node1 podenv=pro
# 创建pod [root@master ~]# kubectl create -f pod-podantiaffinity-required.yaml pod/pod-podantiaffinity-required created
# 查看pod # 发现调度到了node2上 [root@master ~]# kubectl get pods pod-podantiaffinity-required -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE .. pod-podantiaffinity-required1/1 Running 030s 10.244.1.96 node2 ..
# 创建pod1 [root@master ~]# kubectl run taint1 --image=nginx:1.17.1 -n dev [root@master ~]# kubectl get pods -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE taint1-7665f7fd85-574h41/1 Running 02m24s 10.244.1.59 node1
# 创建pod2 [root@master ~]# kubectl run taint2 --image=nginx:1.17.1 -n dev [root@master ~]# kubectl get pods taint2 -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE taint1-7665f7fd85-574h41/1 Running 02m24s 10.244.1.59 node1 taint2-544694789-6zmlf0/1 Pending 021s <none> <none>
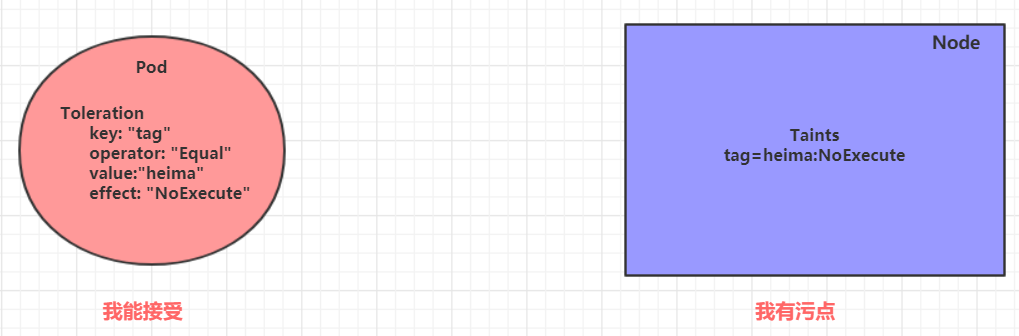
# 添加容忍之前的pod [root@master ~]# kubectl get pods -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED pod-toleration0/1 Pending 03s <none> <none> <none>
# 添加容忍之后的pod [root@master ~]# kubectl get pods -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED pod-toleration1/1 Running 03s 10.244.1.62 node1 <none>